Lista com as melhores ferramentas grátis para raspagem de dados, para usar sem precisar saber programar. Saiba como extrair, hackear ou baixar dados escondidos em documentos pdf ou páginas html. Conversores de PDF para Excel, conversores de PDF para Word, programas para desbloquear PDFs com senha, para escanear texto a partir de arquivos de imagem (OCR) e técnicas de raspagem de dados.
// Best tools for scraping data trapped in pdf files or html pages, to unlock pdf files, ocr image files
Editar PDFs (mesclar, dividir, desbloquear,...)
OCR (digitalizar texto de imagens)
Extrair dados de páginas web (html)
PDF para Excel (PDF to XLS)
Veja aqui mais dicas e as melhores ferramentas grátis para extrair tabelas de PDF para excel: https://www.dadosfinos.info/2023/02/como-converter-pdf-para-excel.html
I Love PDF - PDF to XLS
Conversor online
- Licença: grátis (aparentemente)
- Entrada: PDF
- Saída: XLS, DOC
- Funciona melhor que o Comet Docs
http://www.ilovepdf.com/pt/pdf_para_excel
Comet Docs
Conversor online
- Licença: grátis pra 5 conversões por semana
- Entrada: PDF
- Saída: XLS, TXT…
- Funciona super bem!
Tabula
Desktop (mac/win). Roda no browser (tem uma versão online do Tabula aqui, mas os PDFs ficam públicos no site)
- Licença: Free / Open Source
- Serve pra: Extrair dados de PDFs (tabelas)
- Fácil de usar
- Entrada: PDF
- Saída: CSV ou TSV
- Como usar: desenhar um retângulo sobre uma tabela, e ele identifica os dados e oferece opção de copiar ou baixar. Se o arquivo tiver tabelas idênticas (mesma posição e tamanho) em todas as páginas, tem um botão "Repetir seleção".
- Bom pra PDFs com poucas páginas (se tiver que desenhar a seleção em todas) ou com estrutura idêntica em todas as páginas (pra usar o "Repetir seleção").
PDF to Excel online (Nitro)
Conversor online
- Licença: grátis até 5mb ou 50 páginas
- Como funciona: você envia o arquivo .pdf, o site converte e manda o .xls para seu email
- Se não quiser cadastrar seu email, você pode usar um serviço de email descartável, como o Mailinator (Você entra com um email aleatório, como anabanana@mailinator.com, e clique em Check it pra receber)
- Funciona em alguns casos (pdfs não muito avacalhados)
- Entrada: PDF, DOC, PPT
- Saída: XLS, DOC...
- Limite do tamanho do arquivo: 5mb ou 50 páginas
https://www.pdftoexcelonline.com
Zamzar
Conversor online
- Como funciona: você envia o arquivo .pdf, o site converte e manda o .xls para seu email
- Se não quiser cadastrar seu email, você pode usar um serviço de email descartável, como o Mailinator (Você entra com um email aleatório, como anabanana@mailinator.com, e clique em Check it pra receber)
- Funciona em alguns casos (pdfs não muito avacalhados)
- Entrada: PDF
- Saída: XLS, CSV, DOC...
- Limite do tamanho do arquivo: 10mb
Adobe Acrobat Reader
Desktop (win/mac)
- Licença: Free
- Selecionar, copiar e colar no Excel ou editor de texto.
- Funciona para poucos casos, é bem manual.
- Se você selecionar segurando a tecla Alt, é possível selecionar apenas uma coluna por vez. É bem útil quando os dados estão vindo truncados entre uma coluna e outra.
http://www.adobe.com/products/reader.html
Adobe Acrobat Pro
Desktop (win/mac)
- Licença: paga. Vendido individualmente ($19/mês), ou junto com a suíte Adobe Cloud ($99/mês)
- O Acrobat PRO a partir da versão 10 (X) tem uma função File > Export > XLSX
- Se a tabela não sai perfeita, pelo menos reconhece a maioria dos tabs e separa bem as colunas
- Funciona em quase todos os casos
- Entrada: PDF
- Saída: XLS
http://www.adobe.com/br/products/acrobatpro.html
PDF Tables (do ScraperWiki)
Conversor online
- Licença: grátis pra 5 PDFs
- Entrada: PDF
- Saída: XLS
- Ainda não testei
Tutoriais sobre como limpar PDFs
Convertendo PDFs manualmente pra CSV
Extracting data tables from PDF files (Kaas & Mulvad, DataHarvest 2014)
Simple data scraping using online tools
http://internewskenya.org/fellowshipblog/simple-data-scraping-using-online-tools
How to extract data from a PDF
The Tyranny of the PDF (os problemas do formato pdf)
https://blog.scraperwiki.com/2013/12/the-tyranny-of-the-pdf/
Turning PDFs to Text (da ProPublica, de 2010)
http://www.propublica.org/nerds/item/turning-pdfs-to-text-doc-dollars-guide
Editar PDFs
I love PDF
Conversor online. Dividir, mesclar, comprimir PDFs.
- Licença: free
- Entrada: PDF, XLS, DOC, PPT
- Saída: PDF mesclado, PDF dividido, PDF comprimido
- Merge PDF, Split PDF, Compress PDF, Word to PDF, Powerpoint to PDF, Excel to PDF, PDF to JPG, JPG to PDF
Unlock PDF - I love PDF
Desbloqueador online. Remove senha de arquivos pdf para permitir edição.
- Licença: free
- Entrada: PDF bloqueado com senha
- Saída: PDF desbloqueado (podendo copiar, editar, imprimir conteúdo)
https://www.ilovepdf.com/unlock_pdf
PDF Mergy
Online. Mesclar arquivos PDF
- Licença: free
- Entrada: Vários PDFs
- Saída: Um PDF
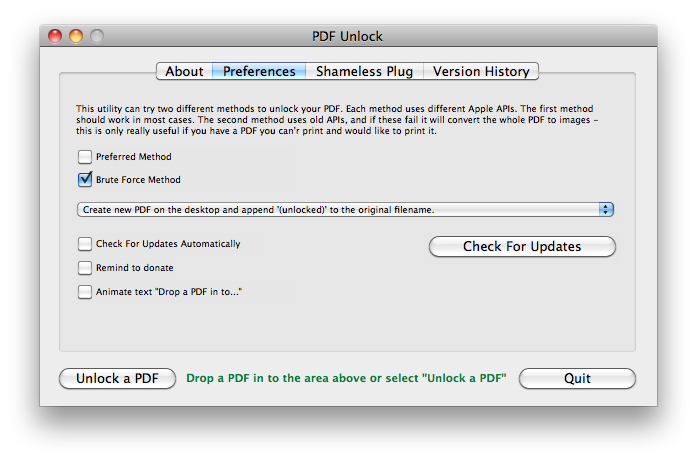
PDF Unlock - Desbloquear PDFs
Desktop (mac)
- Licença: free
- Entrada: PDF bloqueado com senha
- Saída: PDF livre pra copiar conteúdo
- Ajuste as preferências pra funcionar melhor
- Funciona muito bem, com muitos arquivos ao mesmo tempo
{kind=link}
http://www.macupdate.com/app/mac/35106/pdf-unlock
OCR, converter imagens em texto, JPG > TXT
Reconhecimento ótico de caracteres (ou como "ler" documentos que estão em formato imagem, ou em imagens dentro de um pdf). Digitalização/extração de textos que estão em arquivos de imagem, como documentos escaneados (optical character recognition, extracting text from scanned documents, jpg2txt)
OCR no Google Drive
Online
- Super simples e funciona bem
Tutorial rápido:
- Abra drive.google.com com sua conta
- Faça o Upload de um texto em formato PDF ou imagem (JPG, PNG...)
- Clique com o botão direito no arquivo
- Abrir com > Documentos Google
- O Google Drive abrirá um arquivo de texto com o conteúdo da imagem interpretado
Online OCR
Online
NewOCR.com
Online
DocumentCloud (ocr)
Online
- Upload dos documentos
- Reconhecimento de caracteres
- Publicação (dos originais, do texto extraído, das anotações da galera)
- Acesso a jornalistas (1 conta por redação, parece)
ZAMZAR
Conversor online
- Conversor de arquivos (PDF, Excel, …)
- Parece ter função de OCR no caso de upload de imagens
Simile Exhibit
- Analisar documentos, fazer buscas,
http://simile-widgets.org/wiki/Exhibit
Tutoriais de OCR
Scanned Image to Excel Converter
http://www.verypdf.com/app/scan-to-excel-ocr/scanned-image-to-excel-converter.html
Tesseract (ocr)
Engine (não é um software pronto com interface. precisa ser usado com programação)
- Reconhecimento de caracteres
http://code.google.com/p/tesseract-ocr/
Free OCR
Online
Extrair dados de páginas web (HTML)
import.io
Desktop (win/mac/linux)
- Serve para:
- raspagem de dados sem precisar programar
- extrair conteúdo de páginas html e transformar em tabela (download em CSV)
- Parece com o Kimono
- Tem uma versão rápida pra raspar listas: magic.import.io
- Tutorial: scrape without coding with import.io
magic.import.io
Online
- Raspar dados em lista de qualquer site
- Entrada: um URL
- Saída: lista de itens da página (filmes do imdb, produtos da amazon, jobs no linkedin, ...)
- Muito fácil de usar
Kimono Labs (descontinuado)
Agora, versão desktop apenas
- Licença: grátis até 20.000.000 páginas
- Tutorial/demonstração rápida: http://youtu.be/8g6GBjz3K6s
- Pra mim, é o futuro da extração de dados. É genial.
- Ótima e intuitiva interface. É possível fazer tudo sem uma linha de código. Ele cria APIs para extrair o conteúdo uma vez ou ficar rodando frequentemente (1x a cada 15min, 1x/dia, 1x/mês, ...)
- Serve pra: Extrair conteúdo de páginas html. Extrair conteúdo de várias páginas (scrape multiple html pages)
- Como usar: Instalar extensão do chrome ou arrastar o bookmarklet na barra de favoritos (Instale aqui). Abrir página com o conteúdo a ser extraído. Iniciar Kimono. Clicar nos elementos da página que tem a informação desejada. Depois clicar em "Done" pra fazer os ajustes finais ou avançados da API.
- As APIs criadas ficam associadas ao seu login.
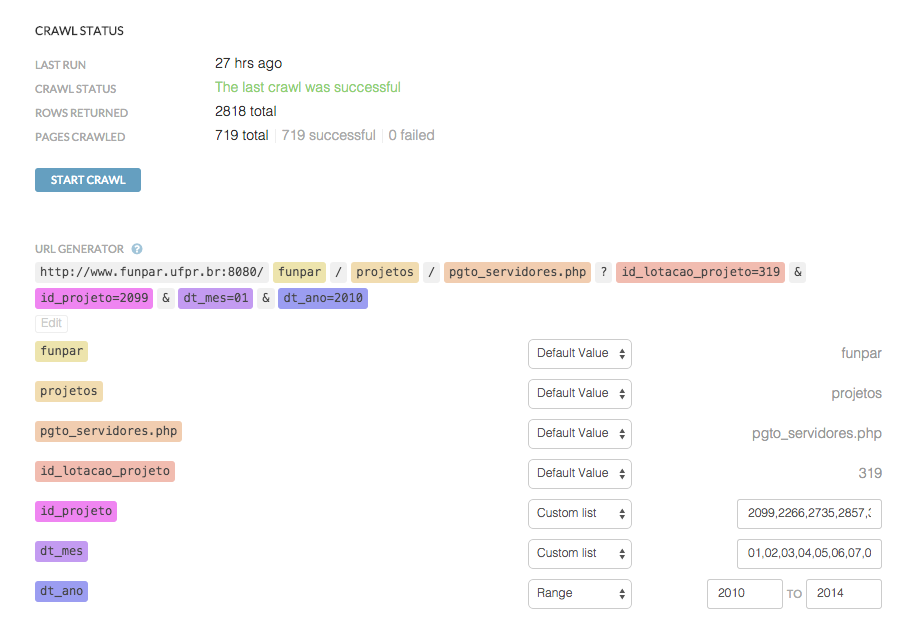
- Tem várias opções para vasculhar mais de uma página: inserir lista pronta de URLs, puxar lista de URLs de outra API feita no próprio Kimono ou gerar lista (Generated URL list). Nesse último, o esquema mais legal, o Kimono identifica os "pedaços" do URL que pode ser variáveis e desmonta a URL pra você escolher se cada parte vai ser fixa (Default Value), numérica (Range) ou uma lista de variáveis, separadas entre vírgulas (Custom list). Entenda melhor nessa imagem
- Ainda tem problemas com: conteúdos carregados dinamicamente
- Saída: CSV, JSON, RSS.
{kind=link}
Google spreadsheets
Online
- Função "importHTML" ou "importXML"
- Serve pra: extrair conteúdo de páginas html
- Bom pra uma ou poucas páginas
- Mantém a tabela atualizada com a fonte (se a página atualizar, os dados no seu google drive também vão atualizar)
http://escoladedados.org/manual/recipes/liberating-html-tables/
Scraper
Extensão do Chrome
- Licença: Free / Open Source
- Serve pra: extrair conteúdo de páginas em html.
- Como usar: clicar com o botão direito em uma informação (ex: uma célula de uma tabela) e "Scrape similar". O plugin vai encontrar estruturas similares (ex.: a tabela inteira)
- Saída: Copiar a tabela do preview ou exportar tabela para o Google Docs
- Funciona legal
- Na maioria dos casos não vai ser muito fácil conseguir todo o conteúdo desejado. Então vai ser necessário um conhecimento básico de html.
- Tutorial: Escola de dados - Scraper for chrome
https://chrome.google.com/webstore/detail/scraper/mbigbapnjcgaffohmbkdlecaccepngjd
DownThemAll
Plugin do Firefox
- Licença: Free / Open Source
- Serve pra: Baixar links ou arquivos em uma página.
- Como funciona: O plugin detecta tudo que tem de conteúdo externo na página (links, imagens, arquivos) e oferece uma janela pra escolher o que baixar.
- Possível Filtrar e escolher como renomear os arquivos
- Funciona muito bem
- Bom pra grande quantidade de arquivos (já baixei mais de 1000 htmls de uma vez)
https://addons.mozilla.org/pt-br/firefox/addon/downthemall/
Outwit
Plugin do Firefox
- Mais difícil de entender como funciona
- Não testei
- Tutorial: scraping without programming
Helium Scraper
Desktop (Win)
- Grátis por 10 dias
- Licença: Paga. Básica: $99
- Fácil de usar, tudo via interface
- Definir campos antes de puxar dados, criar filtros, ...
Google Refine + Scraper (Chrome extension)
- Serve pra: extrair conteúdo de várias páginas html
- Único jeito, fora o kimono, de raspar vários htmls sem programação
- Um pouco complicado de acompanhar
- Tutorial: Scraping multiple Pages using the Scraper Extension and Refine
- Tutorial: Scraping data with Google Refine
- Tutorial: Escola de dados - Scraping multiple Pages using the Scraper Extension and Refine
Tutoriais sobre como extrair conteúdo de páginas html
Escola de dados - Raspagem de dados da internet
Escola de dados - Liberating HTML Data Tables
http://escoladedados.org/manual/recipes/liberating-html-tables/
E-book: Scraping for journalists, Paul Bradshaw
Escola de dados - Introdução ao HTML
http://schoolofdata.org/handbook/recipes/introduction-to-html/
Table Capture - Extensão do Google Chrome para copiar tabelas em html
https://chrome.google.com/webstore/detail/table-capture/iebpjdmgckacbodjpijphcplhebcmeop?hl=en
Interhacktives - Scrape data without coding with import.io
http://www.interhacktives.com/2014/03/06/scrape-data-without-coding-step-step-tutorial-import-io/
Outras coisas
Extrair listas de um site
Online
- Entrada: um URL
- Saída: lista de itens da página (filmes do imdb, produtos da amazon, jobs no linkedin, ...)
Extrair URLs de um texto
Online
- Entrada: um texto, uma lista, o código fonte de uma página
- Saída: apenas uma lista dos URLs limpos que estavam contidos no texto
https://anta.digitalmethods.net/beta/harvestUrls/
Contratando alguém
Uma opção é contratar alguém pra baixar ou limpar os dados. Pode ser útil quando a quantidade de dados é muito grande e não há equipe disponível pra fazer isso. Nunca usei, mas ouvi falar destas opções:
Mechanical Turk
Tutorial: ProPublica's Guide to Mechanical Turk
http://www.propublica.org/article/propublicas-guide-to-mechanical-turk